
뭉크테크
웹 서비스 기본 구조 본문
개요

네트워크같은 인프라구조를 공부할 때 가장 중요한 것이 뭐냐면 전체적인 구조를 이해하는 것이다. 웹서비스에서 쓰이는 기본 프로토콜이 HTTP이다. 근데 HTTP라는 것은 TCP/IP연결 다음에 존재한다. 그러니까 HTTP 트래픽은 소켓 수준에서 만들어진 것이고 따라서 스트림 즉, 끝을 알기 어려운 데이터가 쭉 나열진 형태에서 파생된 것이다.
문제는 네트워크(TCP/IP와 같은 인터넷 네트워크)로 무언가를 보낼 때는 IP 최대크기 단위 MTU가 1500 밖에 안되니까 이 스트림을 TCP 스택 수준에서 짜른다. 이 짤려진 조각 1개를 세그먼트라고 한다면 이 세그먼트를 패킷으로 Encapsulation 해서 전송한다. 이렇게 스트림 데이터는 분해가 일어난다. 그래서 HTTP 트래픽은 가로형태로 데이터를 이어서 이걸 조각내서 패킷으로 만들어서 IP 스택쪽에서 전송을 한다.
그런데 웹 이야기를 할 때는 이런 세그먼트니 패킷이니 이런 이야기는 하지 않는다. 스트림 수준에서 얘기해야하며, 송수신 프로토콜 HTTP는 문자열로 되어 있고 기본구조는 굉장히 간단하다. 즉, 클라이언트에서 문서를 달라 요청하고 서버측에서 문서를 보내는 구조며 이런 과정들이 하나의 쌍으로 이루어진다. 그러면 이 웹서비스 기술들을 종합해서 이야기 해보자.
초창기(팀 버너스리는 무엇을 의도해서 HTTP, HTML을 개발했는가)
앞서 우리가 HTTP를 비롯해서 웹 이야기를 이야기하면서 언급하신 분이 팀 버너스리에 대해 이야기를 하였다. 웹을 이루는 근간의 기술이라는 것은 하나의 HTML인것이고 그것을 실어나르는 HTTP가 가장 기본이 되는 것이다. 초창기엔 PC를포함해서 위의 그림처럼 PC 1대가 인터넷과 연결되어 있다하고 어떤 서버가 있다 해보자. 그 때 이 서버를 웹서버라 해보자. 근데 사실 이 웹서버와 인터넷 사이에는 장치 3개가 존재하고 이것이 연결되어 있는데 이 장치에 대해서는 나중에 언급하도록 하자. 일단 먼저 PC수준에서 이야기 해보자.
이 PC는 웹 클라이언트인데 기본적으로 브라우저일 것이다. 중요한 것은 웹기술이라는게 HTML과 HTTP로 구현된다고는 하지만 대전제가 무엇이냐면 클라이언트와 서버간에 TCP연결을 전제하고 있다. 그니까 TCP/IP기반에서 연결을 기반으로 HTTP 통신이 이루어지는 것이다. 그런데 연결이라는 애기하면서 상태 이야기를 했었는데 여기서 모순되는게 HTTP의 특징중 하나가 무상태(stateless)를 나타낸다는 것이다. 이 모순점은 있다가 이야기를 이어가도록 하자.
이런 상태에서 팀 버너스리가 초기에 웹을 만드셨을 때 기본적으로 HTML이라는 것은 문서였다. 즉, 초창기 웹 클라이언트에 해당되는 브라우저의 본질은 문서뷰어였다. 그런데 기존의 문서뷰어랑 결정적으로 다른 점은 당대 신기술이였던 인터넷이라는 기술을 적용해서 서버에 있는 리소스를 브라우저에 전달하는건데 즉, 브라우저 주소창에 url을 입력하고 엔터를 치면 해당 도메인을 DNS서버를 통해 IP주소를 획득하고 IP주소를 통해 접속을 하고 TCP연결을 실시하고 그것을 기반으로 HTTP 통신이 이루어진다. 근데 HTTP통신이 이루어지는 시점에서 클라이언트에서 서버쪽으로 request가 나가면 이 때 이 request는 보통 http.request.method==GET 문서를 호출하는 것이다. 그러면 서버는 이러한 request를 받고 해당되는 response 문서를 보내준다. 그러면 클라이언트 입장에서는 요청 url에 대한 화면으로 전환이 된다. 이것이 초창기 웹의 형태였다. 그리고 이 문서 안에는 link가 있으니까 이 링크를 클릭하여 마치 우리가 주소창에 url을 입력한 것처럼 그 과정이 되풀이 되는 거였고 이것이 팀 버너스리가 추구한 초창기 웹의 형태였다.
💡 참고
개발자들은 알만한 이야기인데 소프트웨어를 개발할 때 개발 시, 설계원칙이라는 것이 매우 중요하다. 이 설계원칙을 보면 결국 항상 3가지를 나눠라 되어 있는데 다음과 같다.
1. UI(GUI 등)
2. Data
3. 제어체계
이런 설계원칙의 핵심이 최근 들어서 보면 무엇에 가깝냐면 유지보수 문제와 가깝다. 그래서 이 3가지를 섞어서 개발하면 나중에 이 3가지중에 어느 한가지를 수정하면 다른 부분도 수정을 해야하는 사태가 발생한다. 그래서 가급적 유지보수성을 높이기 위해 이 3가지를 나눈다.
발전(HTTP + CSS +JS)
이런것을 고려해 웹이 어떻게 발전하냐면 처음에는 HTML문서가 잘 전달되니 좋았는데 조금 생각을 해버니 문서를 예쁘게 꾸미고 싶다는 생각이 든 것이다. 그래서 이 문서를 예쁘게 꾸미기 위한 문법들이 개발되고 위의 원칙을 근간해 만들어진게 CSS이다. 즉 이제 요청을 할 때 HTML문서뿐만 아니라 CSS도 요청을 하게 되었다.
이렇게 웹이 발전하다보니 1990년대 중반을 지나면서 새로운 브라우저도 탄생을 하게 되었는데 그것이 책에서 볼법한 브라우저인 NetScape이다.
문서라고 하는게 정적인 문서 즉, 신문이나 책같은 문서였는데 이것을 동적인 요소 + 움직임을 넣어 발전된 문서를 만들려고 시도하였다. 그래서 그렇게 동적인 요소를 넣으려다보니 이 동적인 요소에는 일정의 규칙이 따르기 마련이고 이 규칙이란 것을 script형태로 만들게 되었다.
- 그렇게 탄생한것이 Mocha Script였고
- 이것이 몇 달 뒤에 Live Script가 되고
- 또 몇 달뒤에 우리가 아는 Javascript가 되었다.
이렇게 이러한 노력이 더해지면서 웹은 발전되어왔다. HTML문서만 날라오면 이 문서의 내용을 화면에 렌더링하는데 그 전에 구문분석 과정도 추가가 되었다. 즉, text와 tag부분을 나눠서 이 tag를 해석해서 tag에 맞게 렌더링 과정이 필요했다. 그래서 이런 것들을 해주는 엔진이 나왔는데 바로 parser rendering engine이 포함되었으며 추가적으로 javascript의 등장으로 JS Engine까지 기본 구성요소로 포함되었다.
발전(상호작용과 상태전이 그리고 기억)
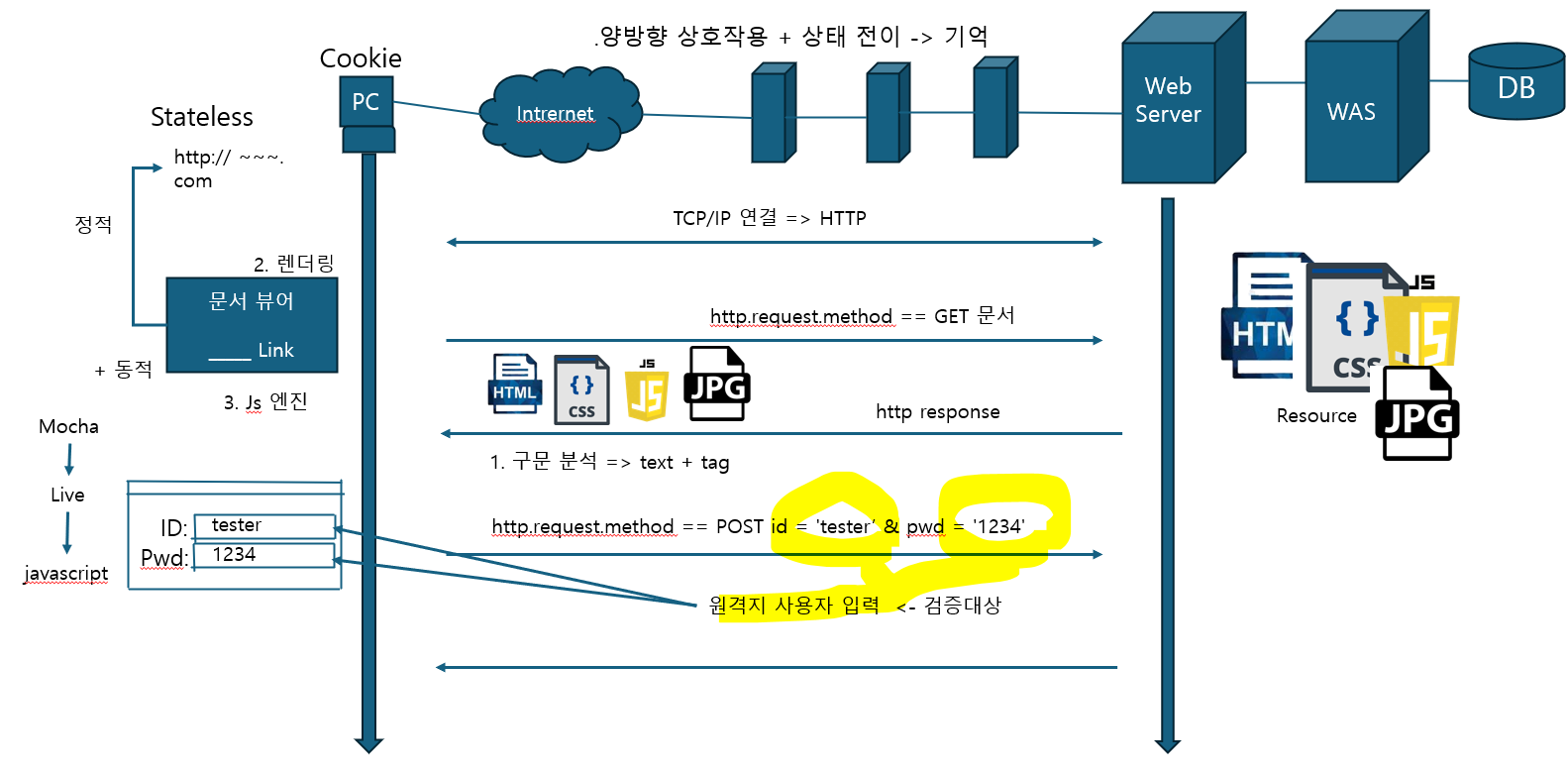
이제 응답을 보낼때 서버는 HTML,CSS,이미지뿐만 아니라 JS도 같이 보낸다. 즉, 정적인 문서에서 동적인 문서형태로 발전되어 왔다. 초창기 웹의 HTTP 메서드로는 GET요청밖에 없었다. 즉, 클라이언트가 HTML문서자료를 요청하면 서버는 그에 맞는 HTML문서를 응답해주는 단방향 상호작용이였다. 즉, 적극적으로 사용자가 개입할 수 있는 형태로 발전되지 못했었다. 이런 부분을 해결하고자 많은 고민을 하게 되고 방법론이 등장하게 되었는데 그게 POST이다. 예를 들어 로그인이라는 시나리오를 생각해보자, ID를 입력하는 창이 있을 것이고 PW를 입력하는 창도 있을 것이고 로그인 버튼도 존재할 것이다. 이 버튼을 클릭하여 POST 메서드를 날려서 양방향 상호작용을 하게 된다.
이 모든 방향성이 양방향 상호작용이 들어가게 되면 필연적으로 따르게 되는게 있는데 그것이 바로 상태전이다. 그런데 HTTP는 stateless이니 이 상태전이를 어딘가에 기억을 시켜야 한다. 근데 이 기억을 클라이언트, 서버 둘다 해야함으로 이 기억을 클라이언트, 서버 둘다 구현이 되어야 할 것이다.
- 클라이언트측에서는 Cookie형태로 기억한다. 이 Cookie는 쉽게 생각해서 상호작용을 위한 기억의 부산물로 암기하자.
- 서버는 여러 클라이언트에 대한 기억을 저장해야하고 양도 방대하다 보니 서버쪽에서 직접 구현을 하지 않고 DB서버를 만들어 저장을 하게 된다. 그래서 웹 서버 외에 DB서버가 생겨난 것이다. 그리고 이 서버에서 클라이언트의 무언가를 기억하게 된다.
그럼 다시 예시로 와서 로그인을 하는데 ID: tester, PW: 1234라고 가정하고 POST를 보내면 ID=tester&PW=1234형태로 넘어가게 된다. 그럼 여기서 관점상 중요한게 뭐냐면 tester, 1234 이런것들이 서버관점에서 원격지 사용자 입력으로 봐야한다. 이 원격지 사용자 입력이라는 것을 서버관점에서는 절대 신뢰해서는 안된다. 이것은 반드시 검증이라는 것을 필요로 한다.
발전(인증 과정)
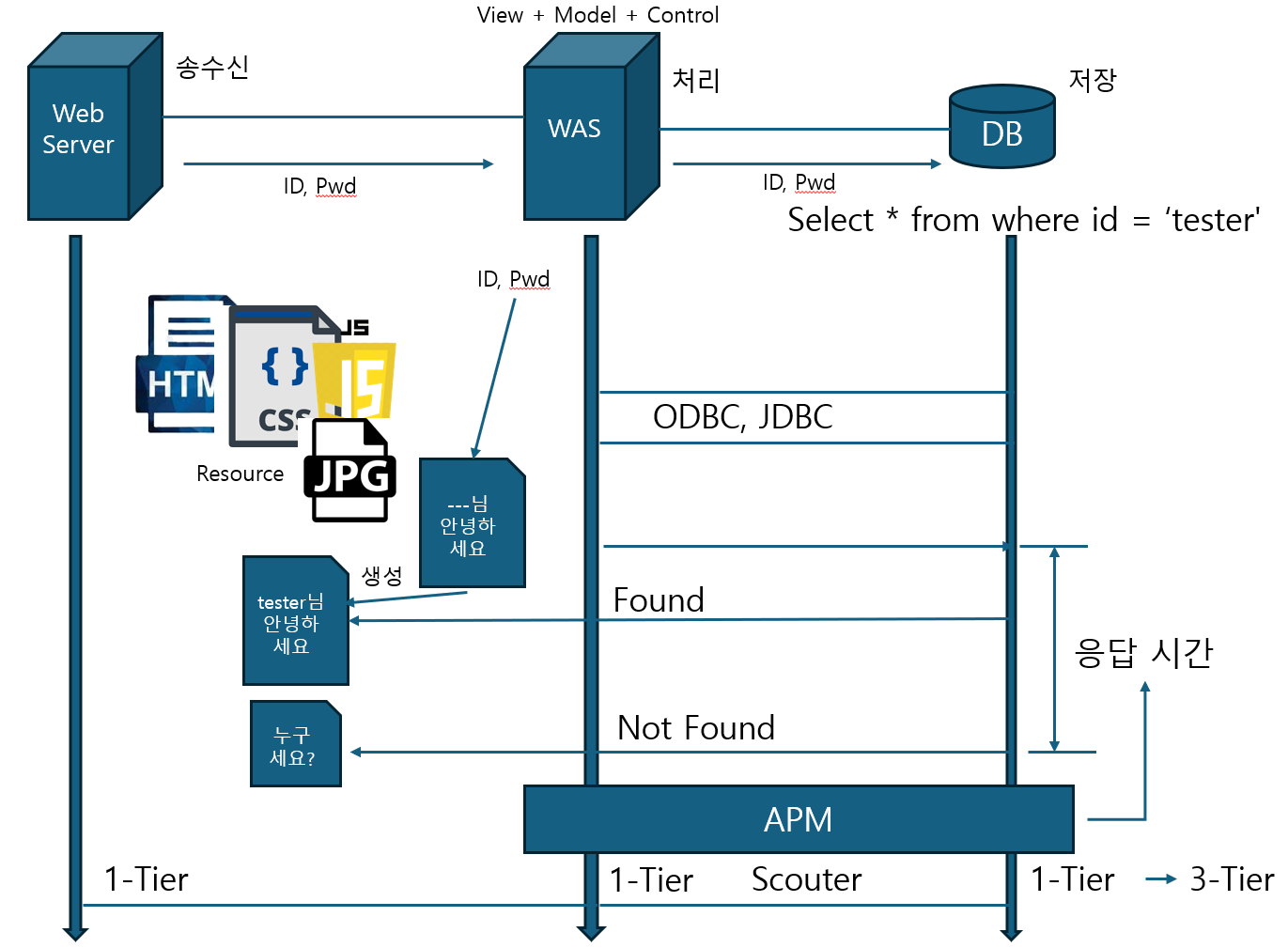
- 그래서 이 검증을 하는 방법으로 넘어온 ID와 PW값을 통해 DB서버에 SQL문 형태로 질의를 하게 된다. 그런데 문제는 웹서버가 DB서버를 직접 두지 않고 WAS라는 중간서버를 두어서 역할을 담당하게 된다. 이 서버를 통해 DB와 연동을 하게 된다. 그래서 역할을 살펴보면 웹 서버는 정적 리소스를 송수신하는 담당을 하고 DB서버는 자료 저장을 담당하며 WAS는 연산을 처리하는 역할을 한다.
- 또한 WAS가 DB서버와 연결할때 ODBC, JDBC같은 인터페이스로 연결이 되어 있고, 웹서버에 넘겨온 검증 값들을 DB서버에 넘겨 SQL문형태로 질의를 하고 질의 결과가 있다면(FOUND) 해당되는 동적 HTML문서를 클라이언트에 넘겨주고 아니면 NOT FOUND에 해당되는 에러 HTML문서를 보여주게 된다.
- WAS 서버를 보면 왼편에는 View부분을 담당하는 웹서버가 오른편에는 Model를 담당하는 DB서버 그리고 WAS 자체의 Control기능이 있다해서 이것을 MVC 구조라고 한다.
웹을 이루는 구성요소가 웹서버도 있고 WAS서버도 있고 DB서버도 있다. 이 3개의 서버를 하나의 무언가로 이어보면 각 서버 하나가 하나의 Tier가 되는거고 이렇게 되면 3-Tier solution이 된다.
웹 서비스 시스템이 얼마나 잘 작동하는지 모니터링하기 마련인데 잘 보면 네트워크가 아무리 빨라도 처리가 늦어지면 안 될것이다. 혹은 처리가 아무리 빨라도 DB서버가 응답을 안하면 굉장히 느려질 것이다. WAS가 무언가를 질의를 할 대 그에 따르는 응답을 보내는데 걸리는 시간 즉, 응답시간이 서비스의 품질을 결정하는데 매우 중대한 역할을 한다. 그래서 이 부분은 집중적으로 모니터링하는 시스템이 있는데 이것을 APM이라고 한다. 대표적으로 Scouter가 있다. 그래서 APM은 기본적으로 응답시간을 모니터링하고 그 다음 WAS도 모니터링 할텐데 그런데 WAS를 이야기 하기전에 잠깐 다른 애기를 좀 해보고 이어가자.
부록(Server side code는 어떻게 실행되는가)
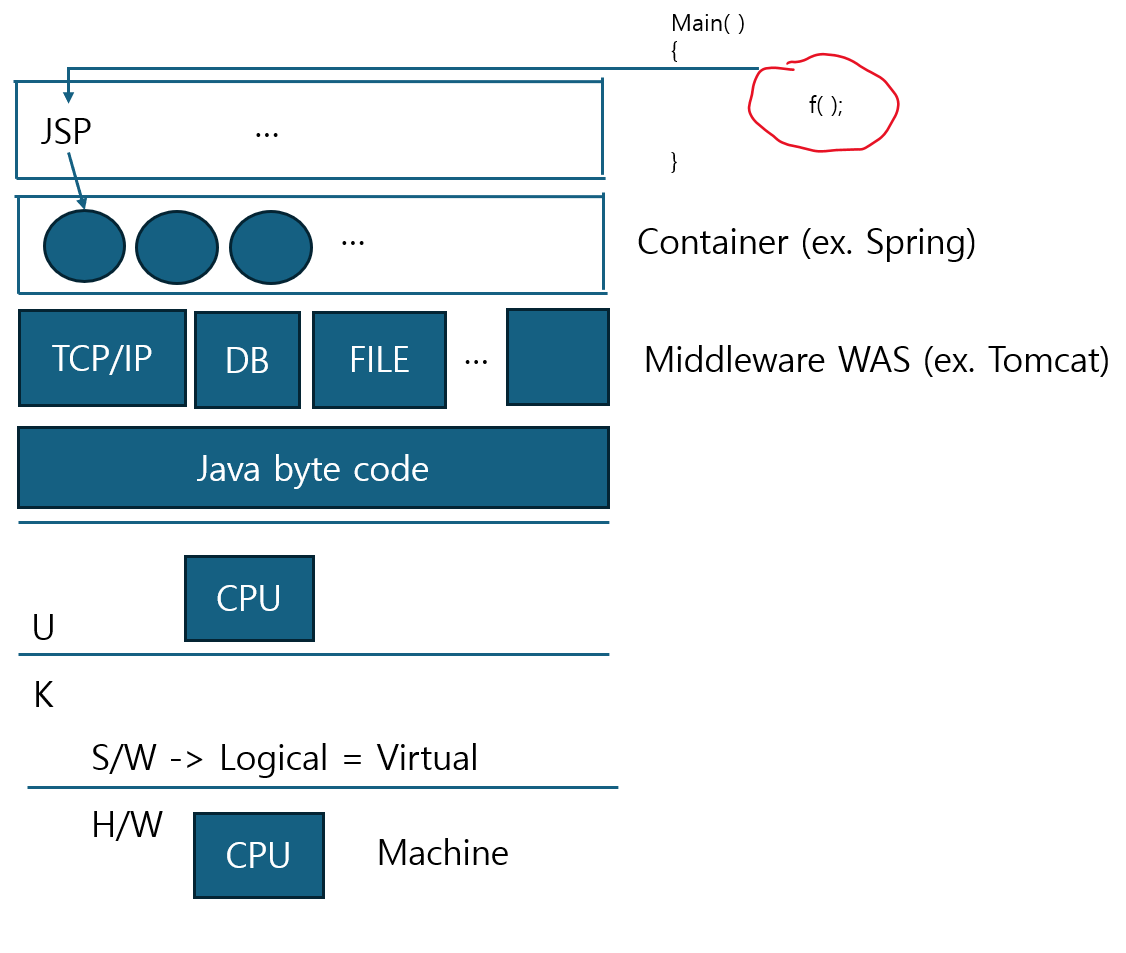
이전 포스트에도 설명했듯이 하드웨어 부분에 CPU가 존재하고 이 하드웨어를 physcial이라고 한다. 그리고 그 이상 부분을 S/W인데 이것을 Logical 혹은 Virtual이라고 한다. 근데 이 이야기를 왜 하냐면 우리나라에서 웹을 한다고 하면 거의 Java + Spring을 이용해서 사용한다. 그럼 자바를 생각해보면 user-mode application 수준에 가상의 CPU를 구현해서 작동하는게 이것이 JVM이다. 그리고 이 CPU가 인식할 수 있는 명령체계가 있는데 그 명령체계가 Java byte code이다.
그런데 문제는 결국 연산을 한다는 것은 Java byte code일텐데 이 Java byte code기반으로 Applciation들을 잘 작동시켜주는 middleware가 있는데 이 middleware라는 것은 또 다른 소프트웨어가 잘 작동할수 있도록 도와주는 소프트웨어이다. 그리고 middleware는 이 소프트웨어들이 잘 작동하도록 필요한 기본적인 기능(TCP/IP, DB I/O, File I/O등) 이러한 기능들을 지원해준다.
그리고 Applciation들을 JSP로 작성하여 만드는데 이것을 JSP로 만들면 이것이 Servlet형태로 변환되어 middleware S/W로 들어가는데 이 Servlet은 미들웨어가 기본으로 지원해주는 기능들을 알아서 가져다 사용할 수 있으니 개발자 입장에서는 편해진다.
쉽게 보면 우리가 C언어에서 test()라는 함수를 실행하기 위해서 main함수를 작성하고 test함수를 작성하고 main함수 안에서 실행해야 하는 과정이 필요하지만 jsp는 test()함수만 잘 작성하면 된다.
이 Servlet 요소들 전체를 감싸는 이것을 Servlet Container라고 하며, 그 밑에 있는 Middleware를 WAS 라고 한다. 대표적으로 Tomcat 같은 놈이 Middleware 중 하나라고 보면 된다.
그리고이 Container 기술중에 기본 기능들을 커스텀해서 지원해주는 프레임워크가 등장했는데 그것이 Spring이다. 결국 Spring도 Container기술인데 결국 객체라는 걸 만들면 의존성을 가지고 어떤 객체를 메모리에 생성했다가 실행했다가 소멸했다 라고하는 이 일련의 과정들을 Spring Container가 알아서 해준다. 그리고 그 객체라는 걸 만들 때도 사용자의 request에 의해 생성된다는 것이다. 이 얘기를 왜 했는지는 아래 APM 얘기와 관련이 있기 때문이다.
발전(서버 성능 유지를 위해 무엇을 봐야하는가)
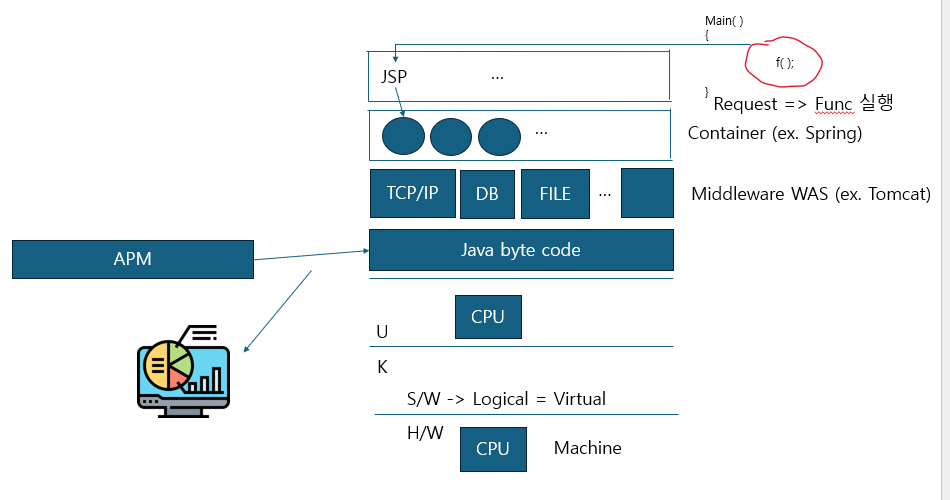
APM 예기로 가서 어떤 장애가 발생했을 때 그 장애를 따라가 원인을 찾아야 하는데 APM은 응답시간도 모니터링 하지만 JVM이 이상없는지를 모니터링해서 chart형태로 보여준다. 사용자의 request에 따라 코드뭉치가 생겨나고 실행되고 사라지고 그런 과정이 있을 것이다. 이걸 Spring Container가 알아서 관리해주는데 이 코드 뭉치는 약간의 함수처럼 생각하면 쉽고 이 함수는 반드시 사용자의 request에 의해 실행된다. 사용자 Request에 따른 API 함수 호출이 제대로 작동은 되는지, 특정 API 호출에 대한 횟수가 너무 높아 시스템이 감당이 되는지 등을 모니터링하는 것이다.
발전(분리 환경과 보안 이야기)
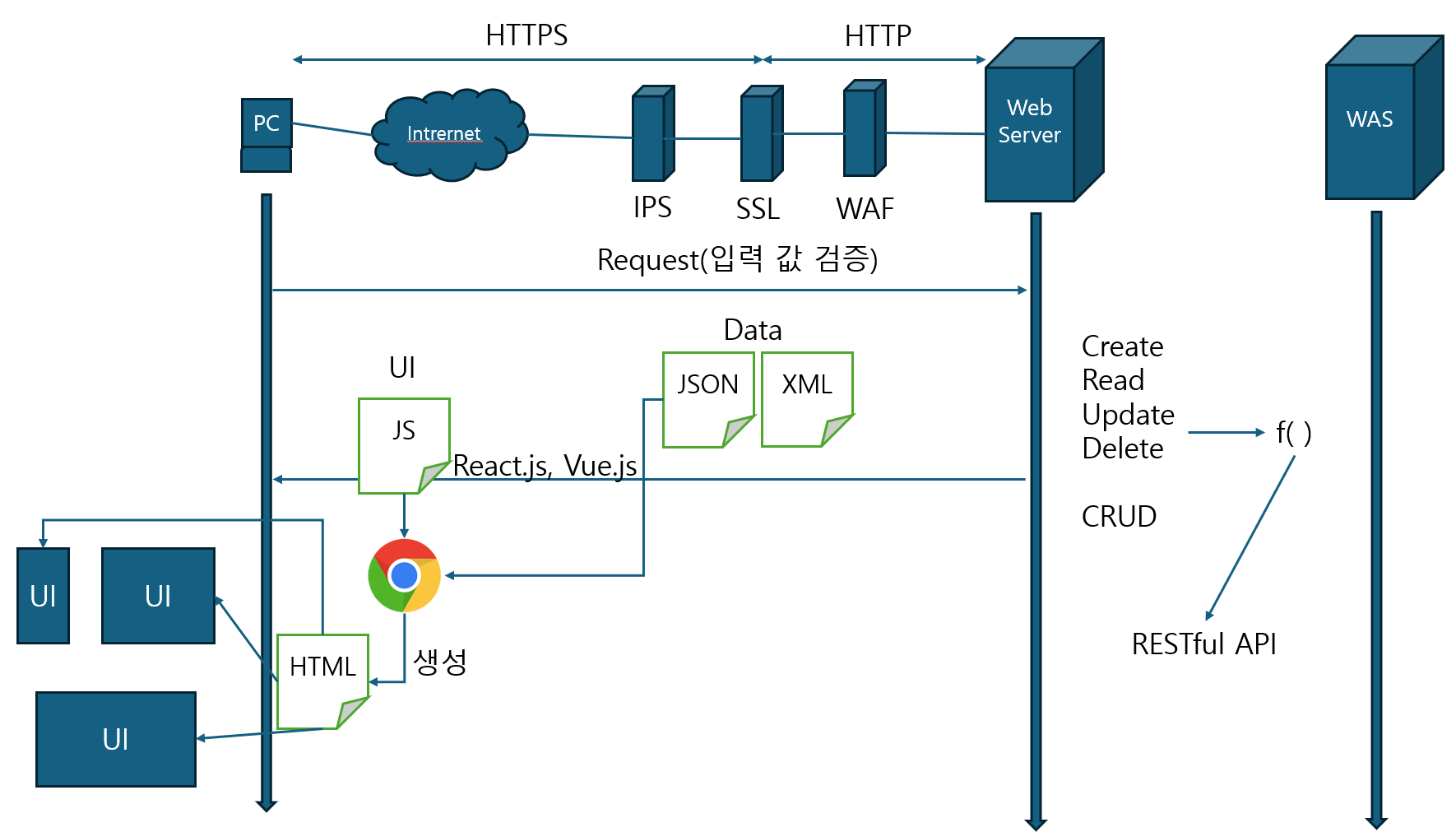
클라이언트에서 화면이 만들어지고 다 좋은데 이 html을 서버에서 만들어서 보내는건데 문제는 이 클라이언트 측 사용자 환경이 매우 다양해지면서 문제가 생겼다. PC뿐만 아니라 모바일, 태플릿등 엄청 환경자체가 다양해지면서 이거를 일일이 다 html로 구현해서 뿌려주기가 번거로워 새로운 생각을 한다.
서버의 request를 보낸다는 관점에서 뭔가를 보내는건 좋은데 response할 때 UI와 data를 분리하자는 시도를 하게 된다. 즉, response할 때 data만 날라오게 하는 것이다. 대표적으로 xml이나 json이 있다. 그래서 날라온 데이터를 JS S/W가 사용자 환경에 맞게 html을 그 자리에서 생성해주는데 이 JS S/W를 구현한 framework가 React, Vue등이 있다. 좀 자세히 말하면, 앞에서 JS 파일도 같이 전달한다고 하지 않았나? 사용자 단의 브라우저 엔진이 해당 JS 파일을 실행시켜 JSON 형태의 데이터를 HTML 템플릿에 맞춰 사용자 화면 UI에 맞게 생성해준다고 보면 된다.
그리고 결국 request를 따라가보면 뭔가를 Create, Read, Update, Delete를 하는건데 그래서 나온게 CRUD이다. 즉, 처리에 대한 request가 된다. 그리고 이 CRUD를 함수형태로 바꿔서 사용하고 이 함수를 호출하면 또 다른 형태가 되는데 이 함수 자체를 URI로 만들어서 기술한게 RESTful API가 되는 것이다.
인터넷과 웹서버 사이 장치가 IPS(보안장치), SSL(암호화 장치, 가속기), WAF(웹서버 방화벽)이 있는데 IPS는 1차 방어체계이고 2차 방어체계가 WAF인데 이 WAF가 웹서버와 WAS사이로 갈 때가 있기도 하다. 또한 SSL은 암호화 하는데 이 SSL장치 왼편 통신을 HTTPS 통신이라 하고 그 오른편 통신을 HTTP 통신이라고 한다. 그리고 사용자의 입력값을 아까 검증해야한다고 했다. 사용자의 입력값 중에 SQL 인젝션 구문이 있을 수 있고, XSS 관련 문구가 삽입되어있을 수도 있다. 이러한 값들을 검증하는게 서버의 몫이다.
출처
외워서 끝내는 네트워크 핵심이론 - 기초 강의 | 널널한 개발자 - 인프런
널널한 개발자 | TCP/IP에서 HTTP까지! 네트워크에 대한 기본 이론이 부족한 분들이 '외워서'라도 전공 이론을 이해하고자 희망하는 분들을 위해 준비한 강의입니다. 할 수 있습니다!, 네트워크, 외
www.inflearn.com
'웹' 카테고리의 다른 글
| 굵고 짧게 살펴보는 HTTP (0) | 2025.01.10 |
|---|---|
| URL과 URI (0) | 2025.01.10 |
| 웹 기술 창시자와 대한민국의 인터넷 (0) | 2025.01.10 |
| 한 번에 끝내는 DNS (0) | 2025.01.10 |



